Sposoby poprawy indeksacji witryny
Nie ma co ukrywać i musisz wiedzieć, że im więcej podstron ma Twoja witryna, tym lepiej dla Ciebie. Dlatego warto regularnie rozbudowywać witrynę i dbać o to, aby była ona poprawnie indeksowana przez wyszukiwarkę. Dzięki temu Twoja pozycja w wynikach wyszukiwania będzie wysoka i stabilna.
Plik robots.txt
Każda strona bezwzględnie powinna posiadać plik robots.txt. Plik ten powinien znaleźć się w głównym katalogu witryny wraz z plikiem index.html. We wnętrzu pliku robots.txt możesz umieścić szereg poleceń, które regulują zasady dostępu do strony przez roboty wyszukiwarek.
Plik robots.txt jest plikiem tekstowym i może mieć na przykład następujący wygląd:
User-agent: *
Disallow:
Polecenie User-agent służy do określania, jakich robotów dotyczy regułka. Bezpośrednio po dwukropku może znaleźć się dokładna nazwa robota lub znak *. Jeżeli skorzystasz z gwiazdki — tak jak w naszym przykładzie — to regułka będzie dotyczyć wszystkich robotów odwiedzających stronę WWW i czytających plik robots.txt. Natomiast podanie konkretnej nazwy powoduje ograniczenie działania wpisu wyłącznie do określonego robota.
User-agent: *
Disallow: /
Jeżeli chcesz zablokować dostęp robota do konkretnego katalogu lub pliku, zapis powinien przybrać następującą postać:
User-agent: *
Disallow: /zablokowany-folder/
Disallow: /zablokowany-plik.html
Pierwsza linia powoduje, że poniższe regułki dotyczą wszystkich robotów. Druga z linii blokuje dostęp do katalogu zablokowany-folder. Natomiast ostatni z wpisów blokuje dostęp do konkretnego pliku o nazwie zablokowany-plik.html.
Na koniec prezentujemy jeszcze jeden przykład pliku robots.txt, w którym blokujemy dostęp konkretnym robotom do całego serwisu oraz chronimy wybrane elementy strony przed wszystkimi robotami.
# Zablokuj następujące roboty:
User-agent: Gulliver/1.3
User-agent: Lycos_Spider_(T-Rex)
User-agent: Scooter/1.0 Disallow: /
# Zablokuj następujące katalogi i pliki:
User-agent: *
Disallow: /prywatne/
Disallow: /cgi-bin/
Linie zaczynające się od znaku # zawierają komentarze i nie mają wpływu na działanie pliku robots.txt. Pierwszy człon wpisu zawiera nazwy robotów, które mają całkowicie zablokowany dostęp do witryny. Korzystając z polecenia User-agent, możemy wymienić wiele robotów, których dotyczy opcja Disallow. Każdy robot powinien zostać wpisany w nowej linii, tak jak to widać na przykładzie. Pamiętaj, że nazwa robota powinna odpowiadać temu, jak dany robot zgłasza się na stronie.
Pomiędzy pierwszy i drugim członem pliku robots.txt znajduje się pusta linia. To bardzo ważne, gdyż na tej podstawie robot wyszukiwarki wie, że ma do czynienia z drugim wpisem. W naszym przykładzie drugi z wpisów dotyczy wszystkich robotów i blokuje ich dostęp do dwóch katalogów o nazwie cgi-bin i prywatne.
Jesteśmy zdania, że należy blokować dostęp do strony robotom, które pracują dla mało popularnych wyszukiwarek. Proponujemy, abyś dokładnie przyjrzał się swoim statystykom odwiedzin i na tej podstawie wytypował listę robotów, które odwiedzają Twoją stronę. Dodatkowo uzupełnij ją o te roboty, które są dla Ciebie ważne i których potrzebujesz ze względu na specyfikę witryny. Następnie zablokują całą resztę.
Przydatne informację na temat robotów i ich bytności na stronie znajdziesz w swoich statystykach. To, jakie roboty Cię odwiedzają i ile pobierają danych, możesz sprawdzić między innymi w systemie statystyk o nazwie AWStats — awstats.sourceforge.net. System jest darmowy, a do jego instalacji wymagane jest konto z dostępem do logów serwera. Warto wspomnieć o tym, że AWStats jest oferowany przez wielu dostawców internetu jako główny system statystyk na ich serwerach.
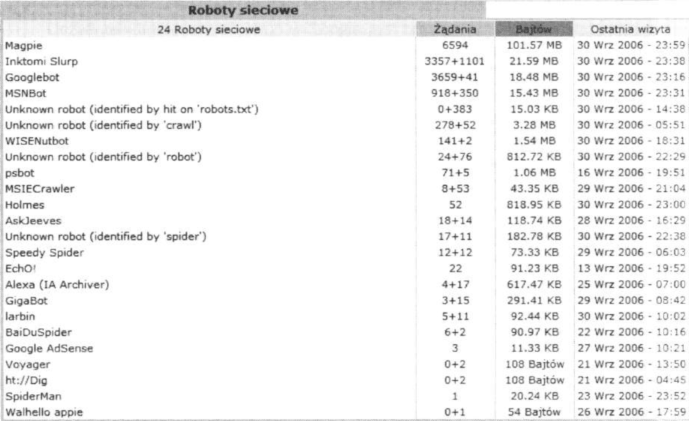 Rysunek przedstawia fragment statystyk generowanych przez AWStats, w którym widzimy podsumowanie pracy robotów w okresie jednego miesiąca na jednej z naszych przykładowych stron.
Rysunek przedstawia fragment statystyk generowanych przez AWStats, w którym widzimy podsumowanie pracy robotów w okresie jednego miesiąca na jednej z naszych przykładowych stron.
W pierwszej kolumnie znajdziesz nazwę robota. Natomiast trzecia kolumna prezentuje informację o tym, ile danych pobrał konkretny robot. Zwróć uwagę na to, że w naszym przykładzie ponad 100 MB pobrał robot o nazwie Magpie. Dzięki danym dostępnym na stronie spiders.pl/baza-browse.php możemy się dowiedzieć, że robot ten należy do strony blueberry.co.uk, która nie jest nam do niczego potrzebna. Wniosek jest prosty: blokujemy robota, dodając następujący wpis do pliku robots.txt:
User-agent: magpie
Disallow: /
Podobnie możemy postąpić z kilkoma innym robotami widocznymi na liście.
Wiele robotów, których obecności na stronie sobie nie życzymy, niestety nie zwraca uwagi na plik robots.txt i w takim przypadku należy im zablokować dostęp. Jak to zrobimy, zależy od możliwości kontroli serwera, na którym jest umieszczona nasza strona.
Jeżeli na serwerze mamy udostępnioną obsługę modułu Apache mod_rewrite i mamy możliwość stworzenia pliku .htaccess, to sprawa zablokowania dostępu niepożądanym robotom jest bardzo prosta. Przykładowy plik .htaccess blokujący robotom dostęp może wyglądać następująco:
RewriteEngine On
Options +FollowSymlinks
RewriteBase /
RewriteCond £{HTTP_USER_AGENT} „fragment nazwy robota” [OR]
RewriteCond *{HTTP_USER_AGENT} „fragment nazwy robota” [OR]
RewriteCond ${HTTP_USER_AGENT} „fragment nazwy robota” [OR]
RewriteCond £{HTTP_USER_AGENT} „ostatni fragment nazwy robota”
RewriteRule .* – [F]
Zablokowanie robotów w ten sposób działa tak, że analizowany jest user agent odwiedzającego i jeżeli zawiera on w sobie ciąg zdefiniowany w poleceniach, to wysyłamy nagłówek 403 (Forbidden). Zdarza się, że niepożądani odwiedzający nie przedstawiają się w sposób łatwy do identyfikacji albo w ogóle pole user_agent jest puste. Wtedy należy zablokować dostęp określonym adresom IP. W pliku .htaccess możemy wstawić następujący kod:
<Limit GET P0ST>
Order allow.deny allow from all deny from 11.22.333.44 deny from 55.68.77.888 </Limit>
Jeżeli nasze konto hostingowe nie pozwala na powyższe rozwiązania, możemy zastosować do zablokowania robotów skrypt PHP. Przykładowy skrypt może mieć następującą formę:
$ua = $_SERVER[HTTP_USER_AGENT]:
$ip = $_SERVER[REMOTE_ADDR]:
nf ( eregi(„fragment nazwy robota”, $ua)
|| eregi(„fragment nazwy kolejnego robota”. $ua) ,
/ / powielamy eregi
|| $ip — „blokowany numer IP”
|| $ip “ „kolejny blokowany numer IP”
/ / powielamy IP > {
header( „location: http://$ip”); II tam, skąd przyszedł, lub w otchłań headerCConnection: close”):
Powyższy skrypt należy umieścić jako pierwszą wykonywaną czynność w kodzie, zanim wyślemy cokolwiek na stronę. Przy użyciu tego skryptu nie blokujemy robotów sensu stricto, tylko wysyłamy je do samych siebie. Ten pomysł zrodził się na forum PiO – forum.optymalizacja.com.
Większość niepożądanych robotów nie honoruje regułek zawartych w pliku robots.txt.
Jedynym skutecznym sposobem na ich zablokowanie są właśnie powyższe przykłady.